你的位置:开云体育(kaiyun)官网 > 开云app下载 >
开云体育app官方最新版 小鹏加速冲向L4终端: 对VLA架构「动刀」成关节一环


剪辑|泽南、杜伟
两个月前的 CES 上,黄仁勋开源了英伟达的首个 VLA(视觉 - 谈话 - 动作)模子,并高调声称物理 AI 的「ChatGPT 时刻」赶快就要到来。
如今,物理世界的 AI 正在成为一个谬误趋势:从机器东谈主到辅助驾驶,越来越多的公司正在尝试用 VLA 模子来重构机器与物理世界交互的神色。
在辅助驾驶领域,端到端的 VLA 措施依然资历了大批考证,杀青了前所未有的效率。干系词,这种架构面对一个自然挑战:手脚中间层的谈话难以好意思满准确抒发现什物理世界的一起细节。李飞飞曾在一次访谈中暗示,「谈话自己只是对物理世界的一种有损抒发。」
在需要及时明白环境并生成驾驶有联想的自动驾驶环境中,通过谈话这一中间层来态状物理世界既有可能引入信息失掉,还会增多畸形推理旅途。跟着驾驶场景复杂度的增多,这种架构颓势制约了系统准确率与效率的赓续普及。
针对这一痛点,小鹏汽车给出的革命性解法是:胜利去掉「谈话转译」门径,在业界初度杀青从视觉信号到动作领导的端到端胜利生成。这恰是其在去年 11 月亮相的第二代 VLA(XPENG VLA 2.0),并在尔后数月完成了 468 个版块更新。
新技能很快产生了质变:在 3 月 2 日举办的「小鹏第二代 VLA 媒体体验日」上,何小鹏晓喻,第二代 VLA 将于本月开启推送。

东谈主们宽阔瞻望,2026 年将成为「物理 AI 元年」。小鹏第二代 VLA 的落地,率先给出了通向十足自动驾驶的「中国谜底」。
跨代级的驾驶体验
在履行体验上,第二代 VLA 的普及主要体面前三大维度:宽解丝滑、全场景才调和高效率。
由于端到端模子的泛化才调,小鹏第二代 VLA 已杀青杀青准确识别各式异形车辆的才调。

即使是对面来车的交通事故,VLA 也能正确识别劳苦物和拦阻道路的车辆,并进行及时的旅途沟通。

在安全和绽开度普及的同期,小鹏的第二代 VLA 成为了实在的「全场景辅助驾驶」,复旧从泊车位、P 挡的原地激活,遮蔽园区小径、乡村土路及无导航谈路,轻率草率小径通行、乡村小径避坑等复杂场景。
在拥堵且复杂的泊车场,第二代 VLA 辅助驾驶不错自动漫游一直穿行到外出,给你充分的时刻开导好导航,不错运转隆重的行程。

这意味着从你上车按下启动键运转,AI 系统就能经受驾驶,实在杀青了从家里车位到公司车位的点到点无缝相接。何小鹏暗示,全场景的辅助驾驶才调将保证在本年年内推出,在统统场景下的辅助驾驶才调齐会像骨干谈通常达到「99 分水平」。
第二代 VLA 的通行效率也有大幅普及,在保险安全的前提下,小鹏实测其概述行车效率普及了 23%。在城市晚岑岭的复杂路况下,其通行效率超越了传统的 L2 智驾和 Robotaxi。
基于这么的才调,第二代 VLA 的使用门槛大幅裁减。何小鹏暗示,好的技能一定要让每一个东谈主齐能用起来,国民的智驾就应该像坐电梯通常轻佻,作念到轻佻、安全且好用。
不外,体验上是很是的轻佻好用,并不虞味着技能上是在原有智驾框架上的轻佻修补。小鹏第二代 VLA 背后,是底层技能架构的一次十足「推倒重来」。
重构技能底座:原生多模态物理大模子
面向 L4 的终极想法,小鹏汽车自客岁运转立项,对端到端的智能驾驶进行了十足的底层重构。
为了将自动驾驶推向物理 AI 的本质,小鹏构建了全经过才调,其中第二代 VLA 是实在作念好高阶自动驾驶的关节技能底座。
第二代 VLA 代表了 AI 驱动驾驶技能的一次谬误架构升级,其不再像传统 VLA 模子那样先通过视觉感知赢得环境信息,再将这些信息鼎新为基于谈话的推理过程,最毕生成车辆的行为领导。
通过引入一种端到端的「视觉 - 动作」(Vision-to-Action)架构,第二代 VLA 使系统轻率将环境感知胜利鼎新为驾驶有联想,普及了举座效率,并显赫加速了系统反应速率。
用一句话归来第二代 VLA:其以赞成模子意会环境感知、场景推理与行为有联想,杀青「感知 — 推理 — 行为」一体化。
在感知层面,通过原生多模态 Tokenizer,艰涩不同模态之间的壁垒,开云体育app杀青了视觉、语音、文本等的赞成编码与交融,对物理世界造成了赞成的明白。
在推理层面,引入超密集的视觉想维链(Visual CoT),轻率对复杂场景进行更高效视觉推理,相较于传统 CoT 推理效率普及约 32 倍。同期相较传统 CoT 瞻望误差裁减 33%,普及系统对复杂驾驶环境的明白与有联想判断。
在行为层面,胜利生成多模态输出,包括语音、视觉反馈以及具体动作和步履。

小鹏通用智能中心负责东谈主刘先明
不仅如斯,小鹏汽车还蚁合北京大学建议了一种全新的视觉 token 剪枝框架 FastDriveVLA,它能让 AI 像东谈主类司机通常,在复杂路况下自动忽略路边的告白牌和无关局面,只盯着中枢路况。
通过让 AI 只专注有用的中枢信息而忽略不消信息,该框架高效贬责了自动驾驶模子 VLA 在处理高帧率图像时带来的超高计较量问题。有关论文已被 AI 顶会 AAAI 2026 接管。

固然,构建出强盛的 AI 底座只是是第一步。在高度复杂的物理世界中,面向 L4 级的辅助驾驶,还必须依托于另外几个中枢因素。
才调公式重构:模子 × 算力 × 数据 × 本色
小鹏建议:第二代 VLA 的突破并非单点才调升级,而是遵守 L4 才调便是「模子 × 算力 × 数据 × 本色」的 Scaling Laws(范围限定)。
正如前沿 AI 技能应用贬抑考证的那样,单纯堆叠通用芯片算力或一味追求高大的模子参数,时常会在履行部署时遭受瓶颈。实在的才调护城河,必须是算法、底层硬件架构与海量数据的深度耦合。
{jz:field.toptypename/}在自动驾驶这个顶级 AI 工程问题上,要想杀青实在的 L4 级自动驾驶,仅靠单一的算法模子突破是远远不够的。系统必须依托车辆这个「物理本色」,在模子、算力和数据三个维度杀青高度协同。
这是一条难而正确的路。
在这其中,既包含了明白实在世界的基础:原生多模态大模子。正如上文所述,小鹏的基座模子杀青「看、听、读」的感官合一,将感知明白、场景推理、行为奉行赞成到并吞模子框架中。

同期也包含了高度优化的软硬件协同,诳骗灵验算力翻开智能的上限。
小鹏在底层算力架构上进行了深度定制。依靠自研的图灵芯片,小鹏杀青了「芯片 - 编译器 - 模子」的蚁合优化研发。通过专诚开导的自动化编译器和基于芯片定制化的图灵结构模子,小鹏最大化了算力的诳骗率,使得模子在车端的运行速率飙升了 12 倍。
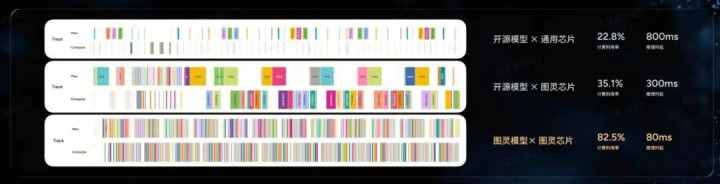
这种深度的软硬件一体化联想,恰是第二代 VLA 轻率及时处理海量视觉信息的底气。
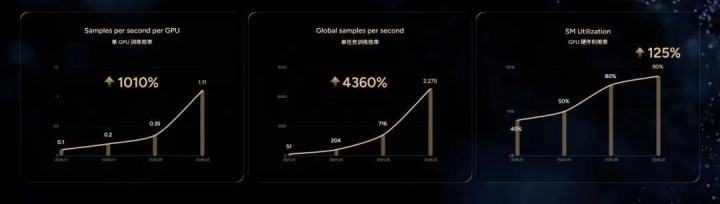
在检会 AI 的过程中,还必须构筑起数据飞轮,让视觉数据的高信息密度价值得以充分开释。
一个值得热心的对比是:现时国内所少见字 AI(主若是各样大谈话模子)的日调用量梗概为 0.737 万亿 Token,而小鹏只是 20 万辆搭载第二代 VLA Ultra 的车辆,每天在车端模子上消费的物理 AI Token 量就高达 58.8 万亿 —— 小鹏车端模子每天消费的 Token,是世界数字 AI 日调用量的近 80 倍。
面前,小鹏依然聚积了超越 50PB 的检会数据,小鹏车端的高清传感器每秒要处理高达 53 亿字节的视觉数据。
终末,这一切齐需要依托强盛的 AI Infra,再通过世界模子的仿真检会杀青闭环。
依托率先的 AI 基础设施,自去年科技日以来,小鹏在半年内完成了 468 个模子的版块迭代。
此外为了草率现实世界中难以穷尽的 Corner Case,小鹏引入了世界模子进行闭环仿真。如今,其仿真场景库已从一年前的 3 万个激增至 50 多万个,每天在虚构世界中进行基于强化学习的「自我对弈」,日均仿真测试里程等效于 3000 万公里的实车测试。
不错说,小鹏第二代 VLA 是一个基于端到端 AI 算法、定制芯片高度整合,由海量数据和世界模子常识共同构建的超等物理 AI 人命体。
结语
跟着新一代 VLA 智能驾驶的出现,物理 AI 的实力正在缓缓展现。

何小鹏暗示,基于端到端模子的辅助驾驶才调将会成为汽车行业改日三年的谬误突破,它是面向十足自动驾驶的第一个版块。在小鹏里面,该技能正在夙昔所未有的速率迭代。
关于一家车企而言,第二代 VLA 是小鹏在自动驾驶技能旅途上的一次谬误探索:不同于传统驾驶系统各个模块(如感知、沟通、扫尾)逐个优化的工程化想路,其围绕自研基座模子打造赞成的物理世界智能系统,从而具备明白实在世界并执续学习、演进的才调。
跟着自动驾驶技能加速迈向 AI 驱动的智能期间,这种技能体系例必成为其鄙人一阶段竞争中争夺主动权的关节变量。
 备案号:
备案号: